

Introduction
Jupyter Notebooks are vital for statistical analysis. They make data science more accessible. With Jupyter, you can combine code, visualizations, and documentation all in one place. Integrating Python libraries enhances statistical analysis capabilities. If you’re looking to dive deeper into Jupyter Notebooks, check out Jupyter Notebook for Data Science: A Complete Guide for a comprehensive understanding!
Summary and Overview
Jupyter Notebooks are interactive web applications that support coding in various languages, primarily Python. They allow data scientists to analyze and visualize data effectively. Statistics play a crucial role in interpreting results and making informed decisions. Key concepts like descriptive and inferential statistics can be implemented easily. This article will guide you through understanding Jupyter Notebooks, their setup, and practical applications of statistics within them. Sections will cover essential statistical concepts, data visualization techniques, and case studies to illustrate the power of Jupyter in data analysis. If you’re just getting started with programming, consider picking up Python Crash Course: A Hands-On, Project-Based Introduction to Programming.

Understanding Jupyter Notebooks
What is Jupyter Notebook?
Jupyter Notebook is an open-source web application that provides an interactive coding environment. Users can write and execute code in small chunks called cells. Each cell can contain code, visualizations, or narrative text, allowing for a fluid workflow. Unlike traditional coding environments, Jupyter promotes real-time feedback and experimentation.
One significant advantage is its support for interactive coding. You can visualize data instantly using libraries like Matplotlib and Seaborn. Jupyter also supports multiple programming languages, including Python, R, and Julia, enhancing its versatility. Markdown integration allows for rich documentation, making your notebooks informative and easy to share. If you want to master data visualization, consider picking up Data Visualization: A Practical Introduction.
As of today, Jupyter Notebooks have gained immense popularity in the data science community. Surveys indicate that more than 50% of data scientists use Jupyter for their projects. This interactive development environment is ideal for both beginners and experienced professionals seeking to analyze and visualize data effectively.
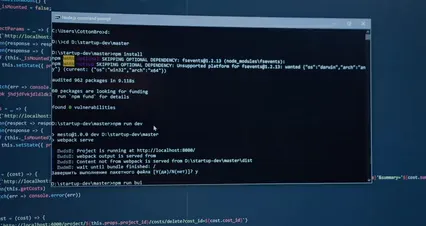
Setting Up Jupyter Notebooks
Setting up Jupyter Notebooks is straightforward and flexible. You can choose between various installation methods, such as pip or Anaconda, depending on your preference.
To install Jupyter using pip, first ensure you have Python installed on your system. Then, open your terminal and run the following command:
pip install notebookThis command installs the classic Jupyter Notebook interface. If you prefer the more modern JupyterLab, use:
pip install jupyterlabFor users who prefer a more comprehensive package, Anaconda is an excellent choice. Anaconda simplifies package management and deployment. To get started, download the Anaconda Individual Edition from their website. After installation, open Anaconda Navigator, where you’ll find both Jupyter Notebook and JupyterLab ready to launch. If you’re looking for more comprehensive insights into data science, The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling is a must-read!
Once you have Jupyter installed, you can create and launch notebooks easily. To start, navigate to your terminal and type:
jupyter notebookThis command opens the Jupyter interface in your web browser. From there, you can create a new notebook by clicking on “New” and selecting “Python 3” or your preferred kernel. Alternatively, in JupyterLab, click on the “+” icon to create a new notebook.
Statistics show that pip is the preferred installation method for about 45% of users, while Anaconda is favored by around 30%. Both methods have their merits, so choose the one that best fits your workflow.
Now you’re ready to start exploring data and performing analyses in Jupyter!

Data Visualization Techniques
Data visualization is essential for understanding statistical data. It transforms complex numbers into visual formats, making insights easier to grasp. When you visualize data, you can spot trends, detect outliers, and communicate findings effectively. If you want to deepen your understanding of statistical learning, consider An Introduction to Statistical Learning: with Applications in R.
Several powerful libraries exist to facilitate data visualization in Jupyter. Matplotlib is a go-to for creating static, interactive graphs and plots. Seaborn builds on Matplotlib, offering enhanced aesthetics and easier syntax for statistical graphics. Plotly takes it a step further, enabling interactive plots that engage viewers.
Creating visualizations is straightforward. You start by importing the necessary libraries. For example:
import matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as pxNext, load your dataset, and select the type of graph that best represents your data. For instance, use bar charts for categorical data or scatter plots for relationships between two variables.
Usage statistics reveal the popularity of these libraries. According to recent surveys, Matplotlib leads with about 80% adoption among data scientists, followed closely by Seaborn at 60% and Plotly at 40%.
In summary, effective data visualization is key in statistical analysis. It not only enhances comprehension but also drives better decision-making. By mastering these tools, you can elevate your data storytelling to new heights. If you’re interested in a practical approach to statistics for data scientists, Practical Statistics for Data Scientists: 50 Essential Concepts is a great resource!
Practical Application of Statistics in Jupyter
Case Study: Analyzing the Iris Dataset
In this section, we’ll conduct a step-by-step analysis of the Iris dataset, a classic in data analysis. This dataset contains measurements for three Iris flower species, making it ideal for exploring statistical concepts.

Step 1: Data Loading
First, we need to load the dataset. You can fetch it directly from a CSV file using Pandas:
import pandas as pd
df = pd.read_csv('iris.csv')Step 2: Data Cleaning
Next, ensure the data is clean. Check for missing values and duplicates:
df.dropna(inplace=True)
df.drop_duplicates(inplace=True)
Step 3: Exploratory Data Analysis (EDA)
Now, let’s perform EDA. Begin by summarizing the data:
summary_stats = df.describe()
print(summary_stats)Visualizing the data is crucial. Use box plots to compare sepal lengths across species:
import seaborn as sns
import matplotlib.pyplot as plt
sns.boxplot(x='species', y='sepal_length', data=df)
plt.title('Sepal Length by Species')
plt.show()
Step 4: Statistical Tests
To analyze differences between species, we can conduct a one-way ANOVA test. This will help determine if there are significant differences in sepal length:
from scipy import stats
anova_result = stats.f_oneway(df[df['species'] == 'setosa']['sepal_length'],
df[df['species'] == 'versicolor']['sepal_length'],
df[df['species'] == 'virginica']['sepal_length'])
print(f'ANOVA Result: F={anova_result.statistic}, p-value={anova_result.pvalue}')Step 5: Interpreting Results
If the p-value is less than 0.05, we reject the null hypothesis, indicating significant differences in sepal lengths among the species.

Step 6: Visualizing Results
Post-hoc tests, like Tukey’s HSD, can further identify which species differ. Visualizations can enhance these findings, making them more digestible for audiences.
from statsmodels.stats.multicomp import pairwise_tukeyhsd
tukey = pairwise_tukeyhsd(df['sepal_length'], df['species'])
print(tukey)Conclusion
Through this analysis, you’ve learned how to load, clean, and visualize data effectively. The Iris dataset serves as a practical example of applying statistical techniques using Jupyter Notebooks. This approach aids in making informed decisions based on data analysis. Engage with your data, and let the insights guide your next steps! Consider broadening your knowledge with The Elements of Statistical Learning: Data Mining, Inference, and Prediction.
Advanced Statistical Techniques
In the realm of statistics, advanced techniques like regression analysis and Bayesian methods stand out. These techniques enhance your ability to make predictions and understand relationships within data. If you want to get hands-on with machine learning, Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow is a fantastic resource!
Simple and Multiple Linear Regression is a foundational method. Simple linear regression explores the relationship between two variables. For example, predicting a person’s weight based on height. The formula is straightforward: y = mx + b, where m is the slope and b is the intercept.
On the other hand, multiple linear regression expands this idea. It analyzes the relationship between one dependent variable and multiple independent variables. Imagine predicting house prices based on size, location, and age. This method allows you to quantify how each factor influences the outcome.
To illustrate, consider a dataset where you predict sales based on advertising spend across various channels. A regression model might reveal that TV ads have a significant effect, while social media ads contribute less. This insight helps in budget allocations for maximum impact.
Bayesian Statistics introduces a different approach. It provides a framework for updating beliefs based on new evidence. Instead of a fixed parameter, it treats parameters as distributions. This concept is particularly useful when you have prior knowledge. If you’re interested in diving deeper into Bayesian methods, Bayesian Data Analysis is a comprehensive guide.
For example, if you know that a certain drug has a 70% chance of effectiveness, but new trial data shows 80%, you can update your belief accordingly. Bayesian methods allow for continuous learning in your analysis.
Both regression analysis and Bayesian methods empower you to perform predictive modeling effectively. By employing these techniques in Jupyter Notebooks, you can visualize results and make informed decisions based on statistical evidence.

Harnessing these powerful tools enhances your statistical toolkit, enabling deeper insights into complex datasets. If you’re looking for a beginner’s guide, A Beginner’s Guide to Data Science is a great starting point!
FAQs
What are Jupyter Notebooks used for in statistical analysis?
Jupyter Notebooks are fantastic for statistical analysis. They allow you to explore and analyze data interactively. You can write code, visualize results, and document findings all in one place. This integration makes it easier to understand complex statistical concepts. The interactive environment encourages experimentation, helping you uncover insights quickly.
How do I install Jupyter Notebooks?
Installing Jupyter Notebooks is simple and flexible. You can use either pip or Anaconda, depending on your preferences. For pip, run `pip install notebook` in your terminal. If you prefer JupyterLab, use `pip install jupyterlab`. Anaconda offers a bundled solution, making it easy to manage packages. Just download Anaconda, and you’re ready to launch Jupyter from the Navigator.
What libraries are essential for statistical analysis in Jupyter?
Several libraries are crucial for statistical analysis in Jupyter. Pandas is great for data manipulation and analysis. NumPy provides support for numerical computations, while Matplotlib and Seaborn excel in data visualization. Scikit-learn is essential for implementing machine learning algorithms. Together, these libraries form a powerful toolkit for statistical analysis.
Can Jupyter Notebooks be used for machine learning?
Absolutely! Jupyter Notebooks are widely used for machine learning projects. They allow for easy experimentation with algorithms and model training. You can visualize data and results, making it easier to understand model performance. With libraries like Scikit-learn and TensorFlow, you can implement machine learning workflows seamlessly.
What are some common statistical tests performed in Jupyter?
In Jupyter, you can perform various statistical tests. Common ones include T-tests for comparing means, ANOVA for analyzing differences among groups, and chi-square tests for categorical data. Regression analysis helps in understanding relationships between variables. Each test provides valuable insights into your data, guiding decision-making processes.
Please let us know what you think about our content by leaving a comment down below!
Thank you for reading till here 🙂
All images from Pexels


